
- Thomas Pollinger
- 08.04.2019
- DE
RQL-Befehle in benutzerdefinierten Aufträgen: Übersicht
Wie schon auf dem letzten WSM-Camp in Karlsruhe angekündigt, werde ich mich in dieser Artikelserie den s.g. RQLCommands bzw. RQL-Kontrollstrukturen widmen. Jedoch bevor wir in die Details an Hand von Beispielen und Erläuterungen abtauchen. Gibt es ein paar grundlegende Abläufe und Regeln, welche man beim Einsatz von benutzerdefinierten Aufträgen und RQLs zuvor wissen sollte.
Voraussetzungen
Zum Ausführen von RQL-Befehlen benötigen man einen Management Server-Benutzernamen und das dazugehörige Passwort. Jeder benutzerdefinierte Auftrag mit RQL-Befehlen erfordert eine Anmeldung am System. Danach werden die RQL-Befehle immer im Kontext des aktiven Benutzers ausgeführt, d. h. mit seinen Rollen, Projektzugriffen und Systemberechtigungen.
Benutzerdefinierte Aufträge werden vom Management Server solange abgearbeitet, bis folgenden Zustände eintreten:
- es wurden alle RQL-Befehle bis zum Ende abgearbeitet
- es wurde ein Fehler bei der Verarbeitung eines RQL festgestellt
Hinweis: Bei jedem RQL-Befehl wird geprüft, ob ein Fehler als Antwort zurück kommt. Da dies schon etwas älter ist, werden auch solche Meldungen als Fehler interpretiert, die im Laufe der Zeit zu Warnungen oder Informationen angepasst wurden - denn es wird intern immer noch das Fehlerobjekt befüllt. Dies wäre z.B. die Meldung, dass eine Seite noch verknüpft ist - wobei man jedoch an diesem RQL einstellen kann, dass man die Meldung ignorieren möchte.
Verarbeitung
Ansonsten gibt es für die Verarbeitungszeit keine Limits, auch wenn ein Job mehrere Stunden benötigt. Solange die Systemdienste des Management Servers aktiv sind, werden die Aufträge nach den o.g. Regeln abgearbeitet.
Jeder Auftrag legt automatisch eine Logdatei unter \OpenText\WS\MS\ASP\Log\Reports\ mit dem Namensschema:
Job yyyy-MM-dd HHmmssfff.log
ab, Dies sind dann z.B. so aus:
Job 2019-04-07 050008750.log
Hinweis: Aktuell gibt es keine Möglichkeit, jedenfalls mir nicht bekannt, den o.g. Namen der Logdatei je Auftrag individueller zu gestalten.
Mechanismus
Der interne Mechanismus nachdem die benutzerdefinierten Aufträge abgearbeitet werden, hat eine einfache Struktur:
- Anmelden des Benutzers
- Ersetzen der Platzhalter z.B. [!guid_login!]
- Ausführen des RQL-Befehls
- Abmelden des Benutzers
Wobei Punkt 2 bei einfachen Aufträgen nur ein einfacher RQL-Befehl ist und bei Verwendung mit Kontrolstrukturen schon aufwändiger werden kann. Die einfachen benutzerdefinierten Aufträge mit RQL-Befehlen, wurden bereits in diesen Artikeln beschrieben:
- How-To: Regelmäßige Projektberichte per E-Mail
- How-To: Systemwartung mit benutzerdefinierten Aufträgen
- How-To: Systemwartung mit benutzerdefinierten Aufträgen (Teil 2)
- How-To: Benutzerverwaltung mit benutzerdefinierten Aufträgen
- How-To: Projektwartung mit benutzerdefinierten Aufträgen
Hinweis: Es gibt auch einen guten Artikel zu diesem Thema von Manuel Schnitger mit dem Titel Limited time? Limited experience? More efficiency!
Einzelserver vs. Cluster
Es gibt einen wichtigen Unterschied im Verhalten von benutzerdefinierten Aufträgen zwischen einer Einzelserver- und Cluster-Installation. Alle benutzerdefinierten Aufträge werden in die zenrale asynchrone Warteschlange (Queue) gesteckt. Bei einem Einzelsever wird der Auftrag mit den RQL-Befehlen immer auf der selben Einheit (Server) ausgeführt. Bei einem Cluster sieht das anders aus, dort wird er Auftag mit den RQL-Befehlen von einem beliebigen Knoten innerhalb des Clusters abgearbeitet.
Dies führt dazu, dass man dann auch die Loddateien nur auf dem Knoten findet. Oder wenn es zu Fehlermeldungen kam, dass diese auch nur auf diesem Knoten im wsms.log zu finden sind. Je nach Größe des Clusters, kann dies schon mal recht zeitaufwändig werden - um rauszubekommen was wo nicht funktioniert hat.
Daher empfiehlt sich die OotB-Funktion zur festen Zuweisung des s.g. Ausführender Anwendungsserver bzw. Fallback-Anwendungsserver aktiv zu nutzen:
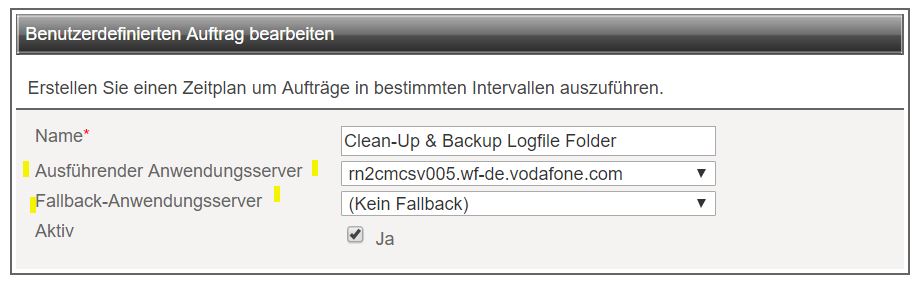
Damit wird sichergestellt, dass die Ausführung des Auftrags immer auf dem selben Clusterknoten erfolgt. Und nur bei einer Störung des primären Anwendungsservers, kommt der Fallback zu Einsatz. Beim Fallback-Anwendungsserver gibt es die folgendne Optionen:
- Kein Fallback
- beliebiger Clusterknoten
- fixer Clusterknoten
Mit dieser Kombination ist man innerhalb eines Clusters vollständig in der Lage, die Aufträge gezielt auf bestimmten Knoten ausführen zu lassen. Ebenso eine Ausfallsicherung, in Form des Fallbacks ist gegeben.
Warum ist diese Funktion so wichtig?
Es gibt durchaus Fälle, in denen nur bestimmte Knoten innerhalb eines Clusters benötigte Netzwerkstrecken oder Laufwerke im Zugriff haben. Oder man möchte vermeiden, dass lastintensive Aufträge auf den Knoten der Editoren laufen usw.
Hinweis: Es ist wichtig sich voher Gedanken zu machen, damit klar ist was, wann und wo ein solcher Auftrag erreichen und auch ggfs. anstellen kann.
Fazit
Der Einsatz von Ereignis- oder Zeitgesteuerten benutzerdefinierten Aufträgen ist ein hilfreiches Mittel. Vorallem wenn RQL-Befehle inkl. Kontrollstrukturen zum Einsatz gebracht werden. Damit lassen sich viele Massverabeitungen, Systemtests oder Wartungsarbeiten automatisieren. Jedoch sollte man sich immer gründlich Gedanken machen über die Zugriffsrechte des Benutzerkontos, der ausführbaren RQL-Befehle und welche Projekte oder Systembereiche davon angesprochen werden. Es empfiehlt sich immer sowas in einer eigenen Umgebung oder mit eingeschränkten Projekt- und Systemzugriffen vorher zu testen.
Im nächsten Artikel mit dem Titel RQL-Befehle in benutzerdefinierten Aufträgen: Platzhalter werden wir uns der Platzhalterlogik innerhalb der RQL-Befehle widmen. Die nachfolgenden Artikel werden dann die Kontrollstrukturen und Einsatzbeispiele beschreiben. Also bleibt am Ball und schaut regelmäßig bei uns vorbei ;)
Über den Autor:
... ist Senior Site Reliability Engineer bei der Vodafone GmbH in Düsseldorf. Seit dem Jahr 2007 betreut er zusammen mit seinen Kollegen die OpenText- (vormals RedDot-) Plattform Web Site Management für die deutsche Konzernzentrale.
Er entwickelt Erweiterungen in Form von Plug-Ins und PowerShell Skripten. Seit den Anfängen in 2001 (RedDot CMS 4.0) kennt er sich speziell mit der Arbeitweise und den Funktionen des Management Server aus.