
- Christoph Straßer
- 21.05.2018
- DE
Liebe auf den zweiten Blick?
Am Beispiel von WSM und GIT.
Präambel
Dieser Artikel soll Gedanken und Überlegungen zu diesem Thema aufbereitet. Manche davon mögen kontroversiell sein. Diese Gedanken und Überlegungen könnten Basis für die Diskussion in der nächsten Usergroup sein.
Ausgangssituation/Motivation/Ziele
| Anforderung | Umsetzung mit WSM-Staging |
|---|---|
| Transport von Änderungen zwischen WSM-System/Instanzen/Projekten (zB Entwicklung (→ QS) → Produktion) | erfüllt |
| Nutzung von Standard-Prozessen und -Werkzeugen aus der Softwareentwicklung für Versionskontrolle | Nicht erfüllt |
Herausforderung: ergänzen
Das Staging-Feature des WSM wird als leistungsfähige Funktionalität anerkannt, in welche wohl viel Zeit und Energie investiert wurde. Das Ziel Änderungen von „Entwickler“-Objekten wie Contentklassen (samt Rattenschwanz wie Elementdefinitionen, Assets, Seitendefinitionen, …) zwischen WSM-System/Instanzen/Projekten kann weitgehend als erfüllt angesehen werden.
Als Eigenheit (bzw. je nach Sichtweise auch „Makel“) bleibt, dass WSM wie auch viele andere WCM-Systeme ein „Insel“ bleibt, die anders funktioniert als die restliche Softwareentwicklung.
Die Integration eines WCM mit einem VCS stellt eine erhebliche Herausforderung dar, da die Arbeitsweisen beider Systeme wie in der Folge dargestellt wird stark unterschiedlich sind. Die WCM-Systeme bis heute „Inseln“ im Softwareentwicklungsprozess darstellen, da bisher keine praktikablen Lösungen gefunden wurden, das nicht passende passend zu machen.
Es kann auch die Grundsatzfrage gestellt werden, wie sehr die Entwicklung in einem WCM mit dem normalen Softwareentwicklungsprozess übereinstimmen kann/soll/muss.
Git (mit seinen Implementierungen Github, Gitlab oder Bitbucket) stellt 2018 den De-Facto-Standard für VCS dar. Anbindungen an weitere VCS wie zB Subversion, Mercurial oder Team Foundation Server sind als wenig prioritär zu betrachten.
VCS (am Beispiel von GIT)
Arbeitsweise
Im Regelfall Text-basierter Content in Form von Sourcecode ist in Ordnern organisiert. Diese Ordner können abhängig von der Programmiersprache mit Packages oder Namespaces übereinstimmen. Dazu kommen in manchen Fällen noch binäre Contents wie zB Bilder.
Der Text-basierte Content (=Sourcecode) ist für den Menschen lesbar. Beziehungen zwischen den einzelnen Sourcecode-Dateien (~Klassen) sind mit den Mitteln der jeweiligen Programmiersprache gelöst. (zB (Java) import com.mycompany.example.model.Person; bzw. (C#) using com.mycompany.example.model;)
Beispiel-Struktur:
- Ordner/Package com.mycompany.example
- Ordner/Package com.mycompany.example.model
- Klasse/Datei com.mycompany.example.model.Person
- Klasse/Datei com.mycompany.example.model.Veranstaltung
- Ordner/Package com.mycompany.example.service
- Klasse/Datei com.mycompany.example.service.Personenverwaltung
(verwendet u.a. com.mycompany.example.model.Person) - Klasse/Datei com.mycompany.example.service.Veranstaltungsanmeldung
(verwendet u.a. com.mycompany.example.model.Person und com.mycompany.example.model.Veranstaltung)
- Klasse/Datei com.mycompany.example.service.Personenverwaltung
- Ordner/Package com.mycompany.example.test
- Klasse/Datei com.mycompany.example.test.Personenverwaltung
(verwendet u.a. com.mycompany.example.model.Person und com.mycompany.example.service.Personenverwaltung) - Klasse/Datei com.mycompany.example.test.Veranstaltungsanmeldung
- Klasse/Datei com.mycompany.example.test.Personenverwaltung
- Ordner/Package com.mycompany.example.model
Dieser in Ordnern strukturierte Text-basierte Content wird mit Hilfe des VCS versioniert. Es können Branches gebildet werden. GIT ist ein distributed VCS – sprich jeder Entwickler hat seine lokale GIT-Instanz welche unabhängig von der zentralen GIT-Instanz läuft. Zwischen den Branches sowie zwischen den GIT-Instanzen werden Änderungen mittels Push, Pull- und Merge-Requests transportiert.
Durch den Build-Prozess (zB Maven- oder Gradle-Script) werden ausführbare Artefakte (=“Programme“) erzeugt, welche in weiterer Folge im Fall von Backend-Komponenten auf einem (Applikations-)Server oder im Fall von Frontend-Komponenten als (zB) Single Page Application auf einem (Web-)Server zur Verfügung gestellt werden. Die Bereitstellung des ausführbaren Artefakts kann auch in Form eines Docker-Images erfolgen welches alle zur Ausführung benötigten Komponenten enthält.
Es gibt somit eine klare Trennung zwischen Entwicklungszeit und Laufzeit. Die „Schnittstelle“ dazwischen ist der Austausch des vom Build-Server erzeugten „Artefakts“.
Der Build-Prozess wird im Regelfall von einem CI-Server (wie zB Jenkins) ausgeführt. Dies ist nicht mehr Aufgabe des VCS! Der CI-Server lädt den Sourcecode sowie das Build-Script aus dem VCS. Der CI-Server führt im Regelfall weiters automatisierte Tests aus, um die technische und fachliche Korrektheit des Sourcecodes zu prüfen.
Nicht-Ziele des VCS
- Das VCS hat kein Wissen über die Zusammenhänge zwischen den einzelnen Sourcecode-Dateien.
- Prüfung des Sourcecodes (auf Konsistenz, Kompilierfähigkeit, Erfüllung fachlicher Anforderungen, ...); Dies sind Aufgaben der IDE des Entwicklers bzw. der Continous Integration (CI) – Infrastruktur wie zB einem Jenkins.
- Versionierung von Daten(bank)-Strukturen. (zB von Entitäten die im Sourcecode definiert sind und auf Tabellen einer relationalen Datenbank abgebildet werden.)
- Bereitstellung von ausführbaren Artefakten. (Ist im Regelfall ebenfalls Aufgabe des CI-Servers.)
WCM (am Beispiel von WSM)
Arbeitsweise
Jedes Objekt (zB Contentklasse, Projektvariante, Template, Elementdefinition, Asset, …) hat eine GUID. Diese GUIDs stehen miteinander in Beziehung. (zB Elementdefinition ist einer Contentklassse zugeordnet; Template ist der Kombination aus Contentklasse und Projektvariante zugeordnet; Asset kann einer Elementdefinition vom Typ Image oder Media zugeordnet sein, ….)
Daraus ergibt sich die erhebliche Herausforderung, diese WCM-spezifischen Strukturen im VCS in einer für den Menschen lesbaren Form abzulegen. Dies wäre die Voraussetzung um in Git etablierte Prozess wie Push, Pull und Merge zu ermöglichen.
Die vom Staging-Mechanismus des WSM erzeugten Staging-Pakete können durch einen Menschen nicht sinnvoll gelesen werden. Der Staging-Mechanismus basiert darauf, dass diese Staging-Pakete von einem „Programm“ gelesen (Import) und geschrieben (Export) werden. Dieses „Programm“ ist Teil des WSM. Dieses „Programm“ kümmert sich darum, die Staging-Pakete in einer für den Menschen verständlichen Form in einem UI aufzubereiten sowie auf Basis der vom Menschen getroffenen Einstellungen beim Import zu verarbeiten.
Jede Lösung einer Git-Integration wird sich im Vergleich zur normalen Softwareentwicklung „künstlich“ bis „komisch“ anfühlen. In der Softwareentwicklung arbeitet man „nativ“ mit Text-Files (=Sourcecode). In WSM wird dies wohl immer auf einen Import/Export zwischen den WSM-Datenstrukturen in der relationalen DB und irgendwelchen Files hinauslaufen.
Chancen/Möglichkeiten/Gedanken ein Umsetzung
Grundüberlegungen
- Wie wichtig ist uns dieses Feature? Gibt´s in WSM nicht andere, wichtigere Baustellen?
- Scope?
- Welche „Objekte“ sollen von der Git-Integration erfasst werden?
- Welche „Objekte“ sollen nicht von der Git-Integration erfasst werden? (alles unter „Projektstruktur verwalten“)
- Welcher Teil kann/soll von Git abgedeckt werden, was von Staging? Oder überschneidet sich das und greift ineinander?
- Wie schaut der Entwicklungsprozess aus?
- Alle Entwickler arbeiten an einem gemeinsamen (zentralen) WSM-Entwicklungssystem. Übernehmen Änderungen von dort nach QS und/oder Produktion.
- Oder: Jeder Entwickler hat sein eigenes lokales WSM-Entwicklungssystem und will seine Änderungen von dort zuerst mal in das zentrale WSM-Entwicklungssystem übernehmen. Dann weiter nach QS und/oder Produktion.
- Oder: Die Entwickler arbeiten gleich auf Produktion weil das mit der Template-Versionierung meistens gut geht. Und etwaige fehlerhafte Änderungen im SmartEdit/Seitenvorschau auffallen bevor sie publiziert werden?
Möglicher exemplarischer Aufbau einer System/Entwicklerlandschaft mit GIT-Integration:
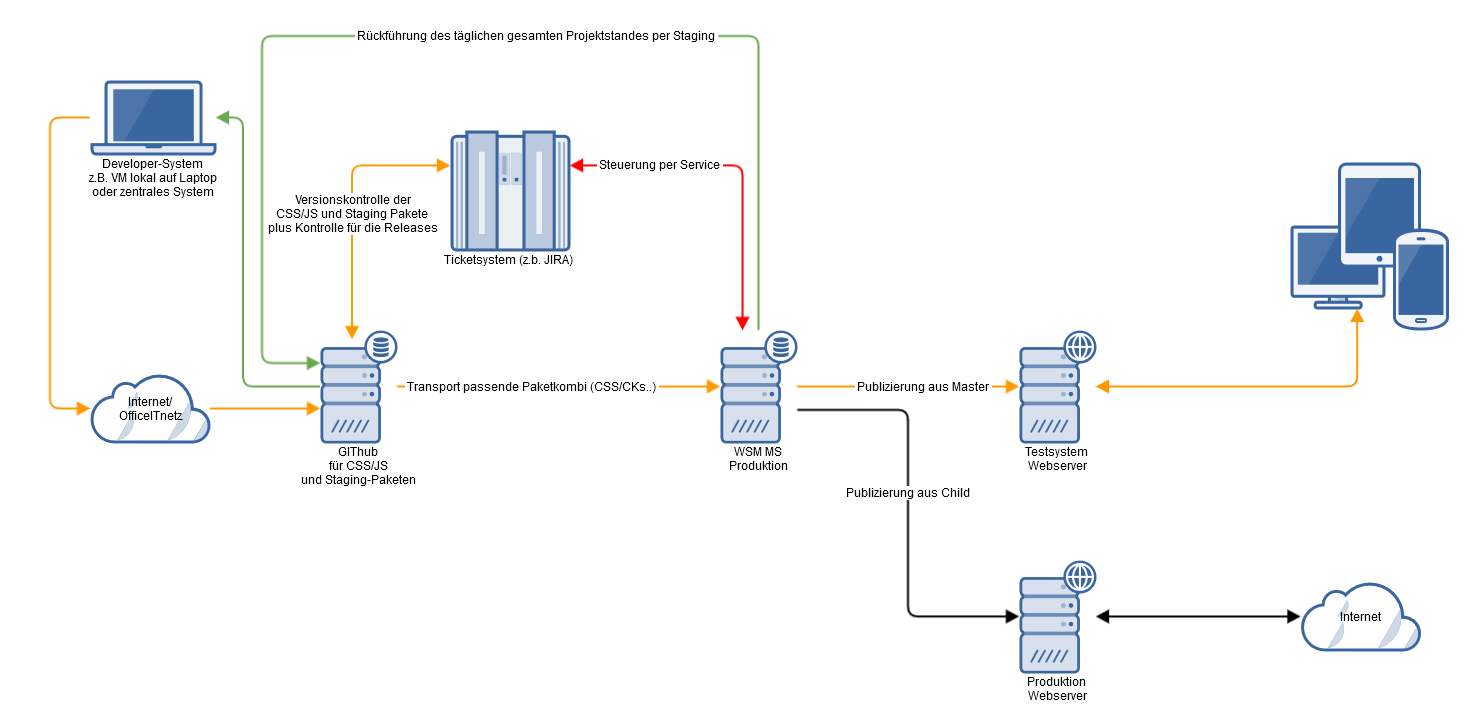
(Umsetzungs-)Möglichkeiten
- Nutzung des VCS als „dummen“ Speicher/Ablageort/Datendrehscheibe für Staging-Pakete. (Anstatt zB eines Fileshares. WSM könnte somit behaupten GIT zu unterstützen. GIT würde aber nicht „im Sinne seines Erfinders“ genutzt werden.)
- Beschränkung der VCS-Integration des WCM auf den Text-Inhalt der Templates (~“Code“). (Hilft das irgendwem???) Dieser könnte zB mit folgender Struktur auf Ordner/Datei in einem VCS
- Ordner com.mycompany.myWsmProject.contentclass
- Datei com.mycompany.myWsmProject.contentclass.templateProjectvariant1
- Datei com.mycompany.myWsmProject.contentclass.templateProjectvariant2
- Ordner com.mycompany.myWsmProject.contentclass
- Aufbauend auf 2.:
- Schaffung einer möglichst menschenlesbarer Repräsentation (JSON, XML, ???) all jener Objekte, welche derzeit bereits vom Staging-Mechanismus erfasst werden.
- Schaffung einer (menschenlesbaren) Alternative zu den GUID´s für die Referenzierung zwischen diesen Objekten.
- Ausdehnung der VCS-Integration auf alles wofür´s diese menschenlesbarer Repräsentation gibt.
Weitere (unstrukturierte) Gedankensammlung
- Automatisierter Import/Export von Staging-Pakete ohne UI? (zB Commandline-Aufrufe, SOAP/Rest-Services, ….)
- Automatisiertes Tracking von Änderungen die durch einen User vorgenommen wurden. Somit automatisierte Ermittlung von „unstaged changes“ welche für ein Staging-Paket (??? oder Commit/Push/Pull-Request, ...) relevant sein könnten.
- WSM könnte Staging-Pakete direkt „nativ“ von/nach GIT lesen/speichern. (Anstatt diese im Filesystem abzulegen) Weitergesponnene Möglichkeit 1 der vorhergehenden Aufzählung. Nur sollten wir das dann noch als Staging-Pakete bezeichnen? Sollen im GIT nicht immer all jene „Objekte“ enthalten sein, die von der VCS-Integration des WSM erfasst werden. (Vergleich mit „normalem“ Programm. Da ist auch der ganze Sourcecode im VCS und nicht nur ein kleiner Teil den wir explizit hineinstellen.)
- Wo passiert der Schnitt zwischen Git-Mechanismen und Staging-Paketen?
Etwaige lokale WSM-Entwicklung und zentrales WSM-Entwicklungssystem unterhalten sich via Git. Alles dahinter (Richtung QS und Prod) dann via Staging-Pakete? Grob vergleichbar mit dem CI-Server in der normalen Softwareentwicklung der das Artefakt für das Deployment produziert. Nur dass hier das Artefakt das Staging-Paket ist.
Und verwendet die Git-Anbindung auch den Staging-Mechanismus oder ist das was Gesondertes? - Wie kann das mit Git-Branches zusammen mit WSM funktionieren?
- … wenn man weiter nachdenkt ergeben sich schnell die nächsten Ideen/Anforderungen/Iterationen...
Persönliches Fazit
Meine persönliche Schlussfolgerung ist, dass es in WSM derzeit wichtigere Baustellen gibt. Wir nach dem vermutlich „großen“ und in Bezug auf Entwicklungsressourcen „teuren“ Staging-Feature nicht noch mehr Entwicklungsressoucen auf eine Git-Integration mit zweifelhaften Erfolgs- und Nutzen-Aussichten investieren sollten.
Wenn einzelne Kunden für sich selber etwas bauen ist das immer zu begrüßen und mgl. lässt sich daraus ja etwas lernen, das später wieder in das Produkt einfließen kann.
Über den Autor:
trägt seit 1998 beim Land Oberösterreich seinen Teil zu einer modernen öffentlichen Verwaltung bei. Nach Anfängen mit Frontpage und ASP in den Anfangszeiten des Internet betreut er seit 2004 Reddot/WSM. Seit rund 10 Jahren liegt der Schwerpunkt seiner Arbeit bei Enterprise Java - Themen. Als Full-Stack-Entwickler deckt er dabei einen weiten Bereich ab, wobei die Schwerpunkte im Frontend-Bereich sowie der Integration von Enterprise-Backend-Systemen via SOAP oder REST liegen.