
- Holm Gehre
- 03.05.2017
- DE
CSV-Dateien mit dem RDB-Dynament verarbeiten
CSV ist in die Jahre gekommen, als Exportformat strukturierter Daten aber immer noch sehr beliebt. Nutzer aus dem Delivery Server Repository können bspw. in diesem Format exportiert werden. Wie sieht es aber mit der Verarbeitung von anderen CSV-Dateien aus?
Im folgenden Artikel möchte ich eine beispielhafte CSV-JDBC Implementierung zur Verarbeitung von CSV-Daten unter Nutzung des Datanbankdynaments (rde-dm:rdb) aufzeigen.
Was ist CSV?
Wikipedia beschreibt CSV wie folgt:
"Das Dateiformat CSV steht für englisch "Comma-separated values" (seltener "Character-separated values") und beschreibt den Aufbau einer Textdatei zur Speicherung oder zum Austausch einfach strukturierter Daten."
Was hat CSV mit Datenbanken zu tun?
Auf den ersten Blick haben die beiden Speicherarten einige Gemeinsamkeiten, die ich mir zu Nutzen mache:
- es werden strukturierte Daten in Tabellen (Datenbanksystem) oder in Textdateien (getrennt durch Komma bzw. einem anderen Trennzeichen) gespeichert
- viele Datenbaksysteme bieten einen Datenexport im CSV-Format oder können dieses als Import-Format lesen
- ...
Die folgendende Unterschiede fallen für meinen Anwendungsfall nicht weiter ins Gewicht, sollten im Einzelfall aber berücksichtigt werden:
- Typisierung von Datenfeldern (Datum, Ganzzahl, Zeichenketten mit Begrenzung der Zeichenanzahl)
- Schlüsselzuweisungen und tabellenübergreifende Referenzen
- ...
Um nun CSV-Dateien mit dem Datenbank-Dynament verarbeiten/abfragen zu können, muss ein entsprechender Konnektor mit einem zugehörigen Datenbanktreiber im Delivery Server eingerichtet werden.
Schritt für Schritt zum Ziel
Die Vorbereitung
Ich habe mich für die Open Source Variante "CSV file JDBC driver" (https://sourceforge.net/projects/csvjdbc/) entschieden und dies wie folgt eingerichtet.
- Download der aktuellsten Version (csvjdbc-1.0-31.jar) (https://sourceforge.net/projects/csvjdbc/files/CsvJdbc/1.0-31/)
- Kopieren/Speichern der JAR-Datei im "tomcat/lib" - Verzeichnis des Delivery Servers
- Neustart des Delivery Servers
Anmerkung: Die JAR-Datei kann auch in jedem anderen Verzeichnis abgelegt werden, in diesem Fall muss der Ablageort dem Klassenpfad hinzugefügt werden.
Neben dem Datenbanktreiber wird auch eine CSV-Datei benötigt. Meine Beispieldatei sieht folgendermaßen aus und stellt den Mitglieder-Daten-Export eines fiktiven Gartenvereins dar.
CSV
MNr,Name,Vorname,Alter,Mitglied seit,Position
1,Mustermann,Klaus,41,01.01.2003,1. Vorstand
2,Mustermann,Helmut,42,01.01.2003,2. Vorstand
3,Mustermann,Gabi,38,01.02.2003,1. Kassierer
4,Mustermann,Helga,39,01.03.2003,2. Kassierer
5,Mustermann,Manfred,45,01.05.2003,Leiter Arbeitseinsätze
Die Einrichtung
Nachdem der JDBC-Treiber installiert und der Delivery Server neu gestartet wurde, ist ein "Neuer Datenbank-Konnektor" (ich habe ihn "CSV-Files" benannt) einzurichten.
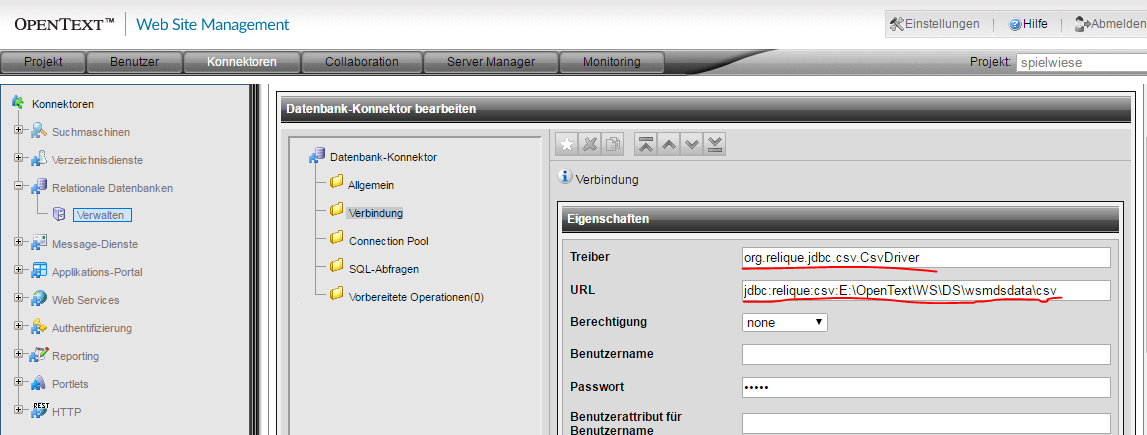
Zu konfigurieren ist unter Verbindung der Treiber und die URL.
Setting Treiber: org.relique.jdbc.csv.CsvDriver URL: jdbc:relique:csv:E:\OpenText\WS\DS\wsmdsdata\csv
Der letzte (rot markierte) Teil der URL ist das Ablage-Verzeichnis der CSV-Datei/en (in meinem Beispiel: "mitglieder.csv" im Verzeichnis "E:\OpenText\WS\DS\wsmdsdata\csv").
Nachdem die Einstellungen übernommen/gespeichert wurden, kann der Konnektor auch wie folgt getestet werden.
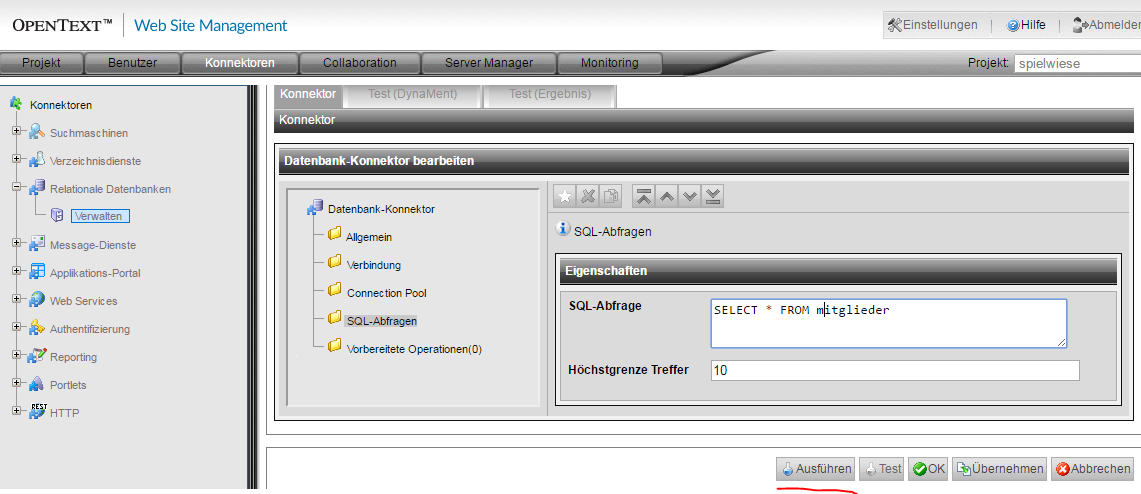
Das Ergebnis ist schon sehr vielversprechend, leider zeigt sich noch ein Encoding-Problem der deutschen Umlaute.
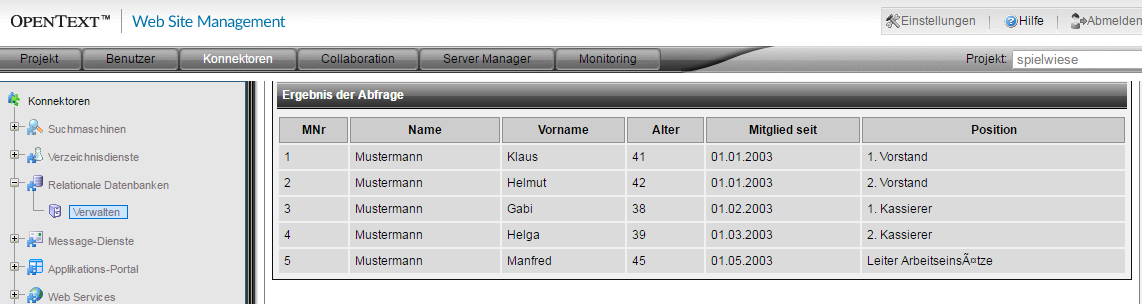
Der CSV-JDBC-Treiber bietet unter anderem die Möglichkeit, ein Encoding festzulegen, im Standard wird das Encoding der JAVA-VM genutzt.
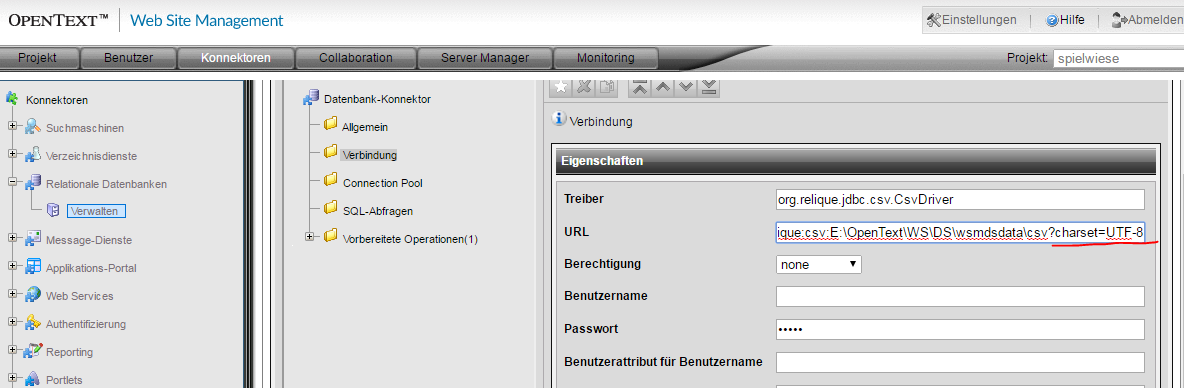
Die URL-Einstellungen haben nun folgendes Erscheinungsbild:
Setting Treiber: org.relique.jdbc.csv.CsvDriver URL: jdbc:relique:csv:E:\OpenText\WS\DS\wsmdsdata\csv?charset=UTF-8
Der Kurztest zeigt nun auch keine weiteren Auffälligkeiten mehr.
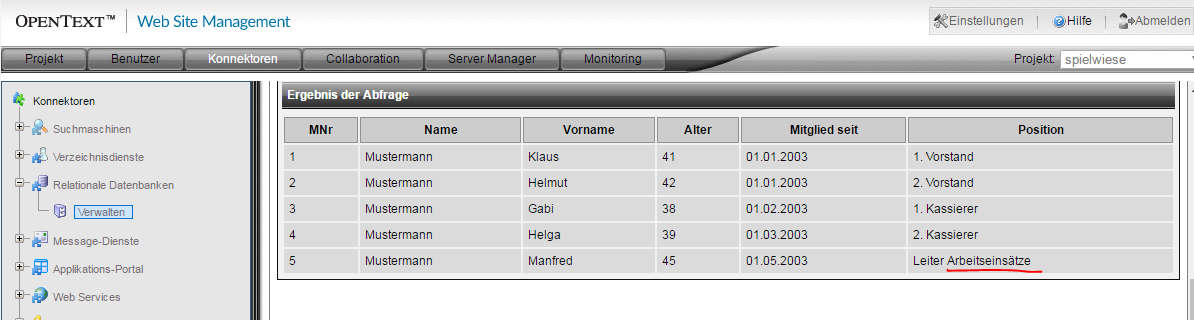
Die letzten Handgriffe
Unter den geschaffenen Vorraussetzungen ist es nun ein Leichtes, die CSV-Datei mit SQL abzufragen. Ich habe im Beispiel eine "vorbereitete Operation getVorstand" erstellt, um die beiden Vorstände des Vereins auszulesen.
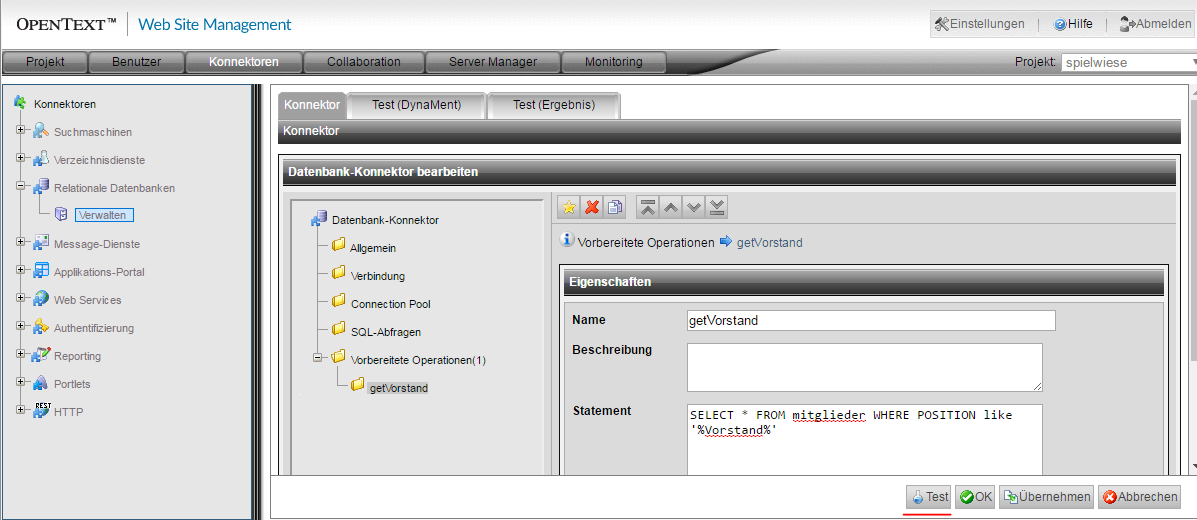
Ein Aufruf von "getVorstand" könnte folgendermaßen mit dem Datenbank-Dynament aussehen:
Dynament <rde-dm:rdb mode='statement' alias='CSV-Files' operation='getVorstand' process-mode='' rde-id='' report-tag=''> </rde-dm:rdb>
Das Ergebnis zeigt auch nur die beiden Vorstände.
XML <result chunk="1" chunksize="1000" description="" hits="2" lastchunk="1" maxchunk-ca="1" maxhits="0"> <row> <MNr>1</MNr> <Name>Mustermann</Name> <Vorname>Klaus</Vorname> <Alter>41</Alter> <Mitglied_seit>01.01.2003</Mitglied_seit> <Position>1. Vorstand</Position> </row> <row> <MNr>2</MNr> <Name>Mustermann</Name> <Vorname>Helmut</Vorname> <Alter>42</Alter> <Mitglied_seit>01.01.2003</Mitglied_seit> <Position>2. Vorstand</Position> </row> </result>
Es ist also ohne viel Aufwand möglich CSV-Dateien zu verarbeiten und für die Erstellung dieses Beispiels habe ich keine 20 Minuten benötigt. Im CSV-Verzeichnis können selbstverständlich viele Dateien liegen, die Auswahl erfolgt über den Dateinamen (ohne die Dateiendung) nach "FROM". In meinem Bespiel habe ich die CSV-Datei "mitglieder.csv" benannt und die Abfrage "... FROM mitglieder" formuliert.
Fazit:
Unter Nutzung eines speziellen "CSV/JDBC-Treibers", können einfache SQL-Abfragen auf eine CSV-Datei angewendet werden. Der im Artikel genutzte Treiber bietet einige zusätzliche Funktionen, auf die ich nicht weiter eingegangen bin, für den einen oder anderen Anwendungsfall aber sicherlich recht nützlich sein können. Einfach in der Doku stöbern und ausprobieren.
Über den Autor:
Holm Gehre ist seit Mitte 2017 Senior Softwareentwickler und Projektleiter bei CHEFS CULINAR und betreut dort mit seinem Team die Opentext-Plattform. Seit dem Jahr 2001 und bis Mitte des Jahres 2017 betreute und entwickelte er Opentext- (vormals RedDot-) basierte Webseiten nationaler und internationaler Kunden auf Basis von Management und Delivery Server.